
type
status
date
slug
summary
tags
category
icon
password
The Way Towards Best Codes
Attention:下面的问题顺序按照倒序来,越早的在越后面
47
46
45
44 如何评估显卡算力
部分数值由于厂家不同,略有出入 | ㅤ | ㅤ | ㅤ |
Nvidia Tesla T4 | Nvidia RTX 3090Ti | 该参数的作用 | |
架构 | Turing架构 | Ampere架构 | |
VERSUS网评分 | 52分 | 94分 | 综合评分 |
Tensor核心数 | 320个Tensor Core | 656个Tensor Core | 张量核支持混合精度计算,动态调整计算以加快吞吐量,同时保持精度。 |
CUDA数量 | 2560 | 10725 | CUDA运算速度只和核心频率有关,而CUDA核心数量则决定了显卡的计算力的强弱。(比如,一项渲染任务,可以拆分为更多份交给不同的CUDA核心进行处理) |
单精度浮点性能(FP32) | 8.1FLOPS | 代表显卡的浮点计算能力,越高算力越强。 | |
半精度浮点数(FP16) | 65TFLOPS | ||
INT4浮点性能 | 260TFLOPS | ||
浮点性能 | 7.76 TFLOPS | 40 TFLOPS | 浮点运算性能是衡量GPU处理器基本马力的方法 |
AI计算运行速度 | 320TFLOPS | ||
显存带宽(存储器带宽) | 320 GB/s | 1008 GB/s | 指显示芯片与显存之间的数据传输速率,它以字节/秒为单位。显存带宽是决定显卡性能和速度最重要的因素之一。 |
显存类型 | GDDR6 | GDDR6X | |
显存大小(VRAM) | 16G | 24G | 是显卡的专用内存。决定batch_size的上限 |
内存总线宽度(显存位宽) | 256bit | 384bit | 更宽的总线宽度代表在每个电脑运行周期能处理更多的数据。(代表GPU芯片每个时钟周期内能从GPU显卡中读取的数据大小,值越大,代表GPU芯片与显存之间的数据交换的速度越快。) |
GPU时脉速度 | 1005MHz | 1670MHz | |
核心频率 | 1582Mhz | 1560MHz | 只显示核心的工作频率,其工作频率在一定程度上可以反映出显示核心的性能。 |
超频频率(GPU TURBO) | 1590MHz | 1890MHz | 当cpu运行低于其限制速度时,其会促进更高的时钟速度,从而获得更高的性能。 |
纹理速率 | |||
像素率 | |||
功率 | 75w | 450w |
1. GPU的计算能力的衡量指标:显存大小、CUDA数量、计算主频;
2. 描述GPU计算能力的指标:计算峰值;存储器带宽;
3. GPU的计算峰值在进行边缘计算的时候是非常重要的。
单精度计算能力的峰值 = 单核单周期计算次数 * 处理核个数 * 主频;
FLOPS是每秒所执行的浮点运算次数,也就是GPU计算的基本单位;TFLOPS: 每秒一万亿次的浮点运算;
GPU计算浮点数的理论峰值 = GPU芯片数量 * GPU Boost主频 * 核心数量 * 单个时钟周期内能处理的浮点计算次数;
4. 带宽:带宽由频率和位宽两个因素所决定;计算公式为:带宽=频率*位宽/8
个人总结:
1. 个人觉得,这么看下来,显卡就是看:能存多少;存的有多快;算的有多快;对应就是:显存大小;带宽;浮点速度;
2. 在不考虑显存上限前提下,带宽,浮点速度同时影响GPU的性能;
3. 从上图所示,T4的处理速度是3090Ti的1/5,但交换速度同时也更慢,在1/3左右。因此T4的整体深度学习速度,大概会在 3090Ti的0.16倍~0.06倍之间;
43 VScode git管理最佳使用教程
42 我要终极解决方案!不再纠结环境!
首先,环境管理肯定用miniconda,省力多了!
其次,确认我的cuda等版本
41 更通透地安装pytorch和tensorflow
Tensorflow2.10版本后不再支持在Windows设备上使用GPU加速,所以windows下Tensorflow支持的CUDA最高版本为11.2;由于之前我安装Tensorflow时安装了11.2版本的CUDA,为了节省空间不安装两个版本的CUDA,这里直接使用11.2版本的CUDA。如果后续因为版本问题需要安装更高版本的Pytorch再安装其他版本的CUDA即可,方法是一样的。
我仔细看了一下,我的cuda在环境变量中的配置就是11.3,以后就安装对应版本的tensorflow吧,也就是2.5
但是,在很多情况下,我的当前环境完全不适配,因此,选择卸载现有cuda,升级到12.4版本,以应对不同挑战
注意:cuda12.4 对应的版本应为
推翻前面的!!!
虚拟环境似乎支持独立的cuda
详见‣结论来说
- 查看tensorflow-cuDNN-cuda之间的对应关系(Build from source on Windows TensorFlow (google.cn))
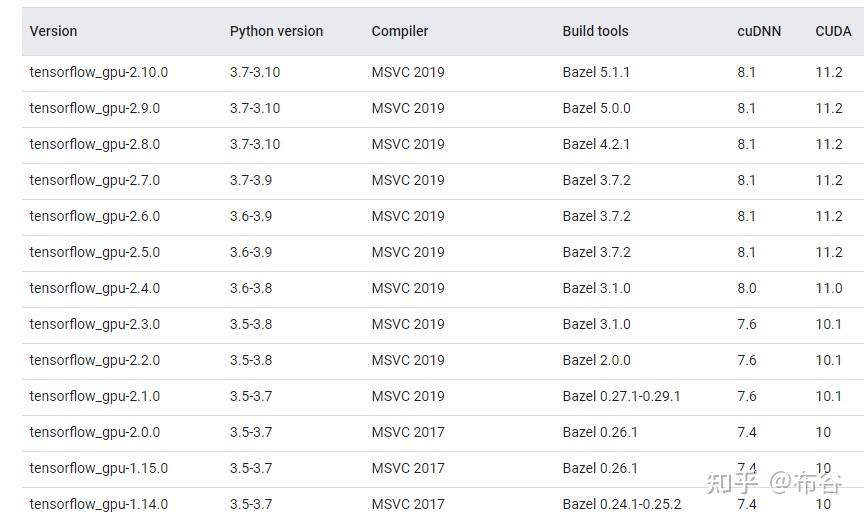
- conda install cudatoolkit=11.2
- conda install cudnn=8.1
- pip install tensorflow==2.6.0安装时间可能久一点,一般是下载时间
- 检查是否安装成功
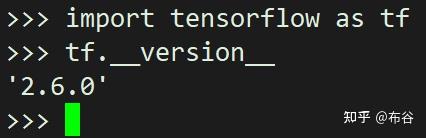
- 查看是否能够加载GPU
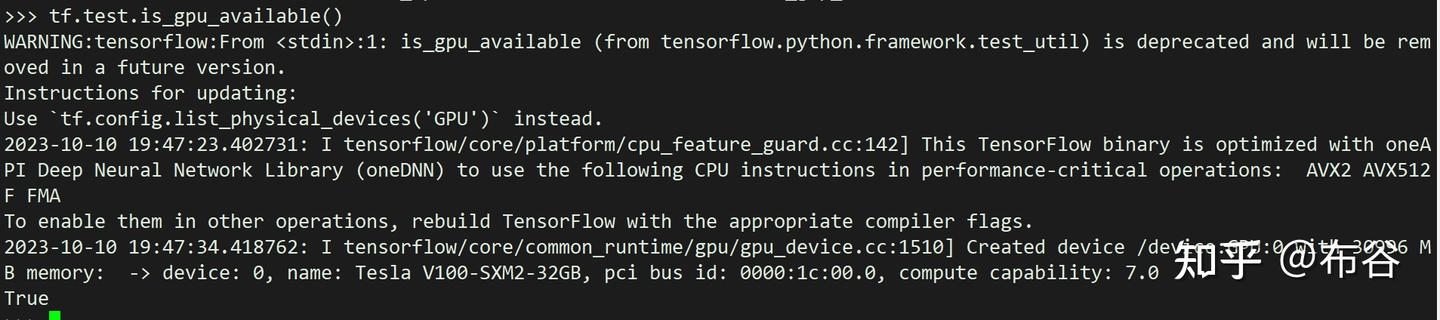
持续报错,上网查询,还要调整keras的版本

pip install keras==2.6
Could not load dynamic library 'cudart64_110.dll’
总结:目前debug不能完全依靠ai,还是得上网
40 在vscode终端打开conda环境
‣
这个照着做,确实有用
核心是新建一个终端配置,并给一下具体的路径参数
39 conda指令复习
删除环境 conda env remove --name 环境名
38 C盘的 Roaming 文件夹可以删除吗?
太长不看版本:不能直接删除文件夹,通过软件删除垃圾文件即可,也可以针对其中没用过的软件进行文件定点清除
可以删除的内容
在 Roaming 文件夹中,有一些文件是可以安全删除的,尤其是那些不再需要或者过时的文件。
1.临时文件:一些应用程序在使用过程中会生成临时文件,如果这些文件不再使用,可以安全删除。2.旧版应用程序数据:如果卸载了一个应用程序但仍然存在其数据文件夹,可以安全删除这些文件夹。
3.备份文件:某些软件会自动创建备份文件,这些文件通常以.bak或.old 扩展名结尾,如果确认不再需要,可以删除。
4.缓存数据:应用程序的缓存数据通常用于加速加载过程,但在一段时间后可能会积累大量无用数据,可以定期清理。
5.配置文件:有时候,应用程序会出现异常或崩溃,导致生成异常的配置文件,这些文件可以手动删除或重命名。
不建议删除的内容
Roaming 文件夹中的一些文件对系统的正常运行至关重要,因此不建议随意删除:
1.系统文件:任何标记为“系统”或“只读”的文件都不应被删除。
2.关键应用程序配置:大多数正规应用程序都会在 Roaming 文件夹中保存必要的配置文件,删除它们可能会导致程序无法正常启动。
3.个人数据:如文档、图片、音频文件等个人数据通常不会放在 Roaming 文件夹中,但如果误将其放在此处,删除前务必先备份。
37 克隆/复制环境Conda
conda create -n B --clone A
B是新环境的名字,A是老环境的名字
36 配置transunet的一些启发
关于pytorch版本适配的问题
注意区分区分 nvidia-smi、nvcc --version、CUDA Runtime 和 pip 安装的 PyTorch
nvcc 是 NVIDIA 的 CUDA 编译器,用于将 CUDA 程序编译成可执行文件。nvcc --version 命令显示的是你系统中安装的 CUDA Toolkit 版本,通常用于开发和编译 CUDA 程序。
CUDA Toolkit 版本:显示当前安装的 CUDA 编译工具的版本,包括 nvcc 编译器、库文件等。这个版本通常用来开发和构建基于 CUDA 的程序。
注意:CUDA Toolkit 版本 和 CUDA runtime 版本 可能不同,尤其是在 GPU 驱动版本较新的情况下。
当你通过 pip 安装 PyTorch(或其他支持 GPU 加速的深度学习框架)时,你实际上是安装了与特定 CUDA runtime 版本 兼容的 PyTorch 库。这些库包含了与 GPU 交互所需的 CUDA runtime,而无需手动安装完整的 CUDA Toolkit。
CUDA runtime:PyTorch 会依赖于你 GPU 驱动支持的 CUDA runtime 版本(由 nvidia-smi 显示)。
CUDA Toolkit:PyTorch 安装包不依赖于 CUDA Toolkit,因此你不需要手动安装完整的 CUDA 编译工具。如果你的系统只安装了 CUDA runtime(通过驱动程序提供),而没有安装 CUDA Toolkit,你仍然可以使用 PyTorch 来加速深度学习模型。
nvcc --version 与 nvidia-smi 显示的 CUDA version 不匹配:这通常是因为你系统安装了多个 CUDA 版本(如 CUDA Toolkit 和 GPU 驱动版本不一致)。nvcc 显示的是 CUDA Toolkit 的版本,而 nvidia-smi 显示的是与 GPU 驱动兼容的 CUDA runtime 版本。
CUDA Toolkit 版本低于 PyTorch 需要的 CUDA runtime 版本:如果你的 CUDA Toolkit 版本 低于 PyTorch 所需要的 CUDA runtime 版本,可能会出现不兼容问题。比如,PyTorch 可能依赖于 CUDA 11.x 或 12.x 的新特性,而你安装的 CUDA 10.2 不支持这些特性。
最重要的一点,可以向下兼容pytorch版本所需的cuda版本,所以我直接装大多数版本其实都行,只要注意一下pytorch版本和工具库就行,比如:

11.3的CUDA版本,1.11.0+cu113的torch版本,但其实我的电脑应该是12.8的cuda
 
35 VR第三方游戏配置
- language schinese -Steam -VR -novid +volume_fog_disable 1
加在快捷方式的属性exe后边
34 神经网络的优化问题
参数量过大从而避免陷入局部最优
33 更优的命名法
下划线规则更佳

32 torch curriculum
x = x.reshape(8,-1) # 这里的-1表示这个维度让torch自动推算,只要第一个维度是8就行
将后续几个维度都变成了一维,一般是直接连接
一个很重要的启示,通过绘制loss的走向可以很明确的理解是不是过拟合,学习率是否合适,如何调整超参数等。
当然更好的方式是用如Adam、Adagrad等,它们可以根据梯度信息自动调节每个参数的学习率,减轻手动设定学习率的压力。
31 卷积神经网络
30 Torchsummary 这个库来看模型结构
from torchsummary import summary
model = Net()
summary(model, input_size=(1, 4, 1050)) # 输入形状 (channels, height, width)
29 神经网络 curriculum
28 Dataloader的一个坑
在 DataLoader 里,PyTorch 默认会 自动堆叠 (batching),如果 labels 长度不一致,可能会自动补全为 最大时间步长 (225)。
在 trainer.fit(model, train_dataloader, val_dataloader) 里:
DataLoader 会 自动将 batch 内样本堆叠,如果 labels 的时间步长 T 不是固定值,PyTorch 可能会自动 pad,导致变成 (batch_size, max_T),而不是 (batch_size,)。
CrossEntropyLoss 只接受 1D 整数索引的标签,但你的 labels.shape = (7, 225),所以报错 multi-target not supported。
27 模式识别·校内
少写code多炼丹
- 优化问题:全局最优的trick——
- 其实使用神经网络的时候参数量都很大,最后其实往往都会训练到过拟合,当模型的参数越多,实际上能拟合的复杂度就更大,也就越容易过拟合,这块好理解
- 针对上述问题,我们往往通过earlystopping来实现拟合
- 训练集与测试集分布不一致,应该通过domainadaption,来进行适应
- 在训练时loss降不下去怎么办——优化问题optimization
- 梯度消失:局部极小or极大,或是 鞍点
- 数学上就是找二阶导,但是实际问题里用hessian矩阵来进行判断,loss函数在此点的泰勒展开来进行数学推导
- Saddlepoint——附近特征根有大于零有小于零
- 另一种思路——退火法,从局部极小跳到全局极小
- 梯度爆炸?
- 常见库Adam
- 医生的问题:多少数据是足够的?实际上:很难确定
26 各种验证集的设置方案
Holdout Validation
在holdout验证中,我们只是执行一个简单的训练/测试分割,在这个分割中,我们将我们的模型适合我们的训练数据,并将其应用于我们的测试数据以生成预测值。 我们“保留”测试数据只用于严格的预测目的。 拒绝验证不是一种交叉验证技术。 但我们必须讨论模型评估的标准方法,以便将其属性与实际的交叉验证技术进行比较。
当涉及到代码时,拒绝验证很容易使用。 该实现很简单,不需要在计算能力和时间复杂度方面投入大量精力。 此外,我们可以更好地解释和理解holdout验证的结果,因为holdout验证不需要我们弄清楚迭代是如何执行的。
然而,在许多情况下,holdout验证并不能保持数据集的统计完整性。 例如,将数据分割成训练和测试部分的holdout验证由于没有将测试数据合并到模型中而导致了偏差。 测试数据可能包含一些重要的观察结果。 这将对模型的准确性造成损害。 此外,除了引入验证和/或训练误差之外,这将导致数据的欠拟合(underfiting)和过拟合(overfitting)。
K-fold Validation
在K-fold交叉验证中,我们回答了许多holdout验证固有的问题,如欠拟合(underfiting)和过拟合(overfitting)、验证和训练误差。 这是通过在某些迭代中使用验证集中的所有观察结果来实现的。 我们计算每k次迭代中计算的所有精度分数的平均精度分数。 通过这样做,我们最小化了可能出现在初步模型验证技术——holdout验证中的偏差和方差。
然而,就计算能力而言,k-fold交叉验证是非常昂贵的。 计算机必须进行几次迭代才能得到正确的分数。 理论上,模型的精度分数随着每增加k次迭代而增加。 这将减少偏差,同时增加variation。 当我们尝试将k-fold验证应用到包含大约58万个观测的非常大的数据集时,我们将在本文后面看到一个例子。
LOOCV
LOOCV 与 K-fold 非常相似,其中 是k 等于整个数据集的长度(或样本/行数)时的特殊情况。 因此,训练集的长度为 k-1,而测试集将是单个数据样本。 LOOCV 在我们的数据集特别小,不适合进行 K-fold 的情况下特别有用。 LOOCV 通常在计算上也非常昂贵,尽管它通常是倾向于在固有较小的数据集上使用。
然而,LOOCV 往往会产生高方差,因为该方法会通过单个测试值检测数据中所有可能的噪声和异常值。 对于非常大的数据集,LOOCV 的计算成本会非常高; 在这种情况下,最好使用常规的 k-fold。
25 Transformer教程
没看完,想先做自己的项目o(╥﹏╥)o
24 个人ai机器人远程云服务器部署
用astrbot + 云服务器
核心操作
Qq开发平台QQ机器人管理端
Astrbot官方文档
阿里云的教程
获取大模型的api
在服务器里部署astrbot然后设置我们的机器人相关参数
配置自己的远程服务器
在腾讯云通过68元/年进行租赁
不要选择没听说过的系统内核
此处我用的是ubantu
注意这里是轻量化服务器,无法进行图形化界面显示。
需要通过云服务器进行托管,用docker部署的时候发现会卡在astrbot下载,于是手动部署,直接上传一下本地的源码,准备配置环境的时候,发现轻量服务器中搭载的ide里边python环境又不响应,搞半天轻量服务器连图形化界面都没有。
sudo docker run -itd -p 6180-6200:6180-6200 -p 11451:11451 -v $PWD/data:/AstrBot/data --name astrbot soulter/astrbot:latest
sudo docker logs -f astrbot
换了一个代码来部署,部署好了又是因为没有图形化界面而打不开astrbot的管理界面,只能先装一个图形化界面,但愿能够有用。——结局,装到90%多不行了,暂时不想折腾了。
这里注意一个很重要的细节:我们安装部署后,里面会给一个local地址,我们能够通过这个地址对机器人进行配置,这里其实轻量服务器是无法打开的,但是神器的是,只需要把“local替换为“服务器的ip”,再加上原本的端口,就可以在自己的本地电脑打开我们的网页从而完成配置。
在云服务器上部署 AstrBot,需要将 localhost 替换为你的服务器 IP 地址。
配置好后挂起就行了,即便关闭了云端服务器的网页也会一直开机。
最麻烦的地方是隐私协议还有审核文档。
23 什么是mne,为什么要用mne
22 很好的网页保存方式
当然是 .mhtm格式!
直接ctrl+s 然后选择这个格式,就能用一个文件保存好网页啦,比pdf舒服多了!
21 更好的注释效果
在 Python 中,函数内部的注释(即 docstring)可以通过在函数定义后面添加一个字符串来实现。在函数名上悬停时,可以看到 docstring,这通常是函数的简要说明。
def sample_entropy(x):
""" 计算样本熵 """
return an.sample_entropy(x)
20 获得上上级目录
from pathlib import Path
# 获取当前文件的路径对象
current_file = Path(__file__).resolve()
# 获取上上级目录
parent_dir = current_file.parent.parent
# 示例:拼接上上级目录中的子文件
target_path = parent_dir / "data" / "file.txt"
print(target_path)
19 print的所有用法
18 Pytorch深入学习
17 几个常见ML模型的数学原理
似乎没那么重要,所以一直没复习……
16 为jupyter配置conda环境
按照这个教程做了,但不知道有没有起作用,
直接在vscode里选择对应内核就可以跑了。
15 GridSearchCV 自动超参数寻优
14 装饰器
@语法就是一个装饰语法
是帽子一样的功能

函数名作为参数传入到装饰器函数里,二者进行关联。
目的是通过多个装饰器,对一个函数进行多次调用,而实现一些有区别的功能。
里面常见的一个操作是传入参数 *args,来表示自己其实不知道里面有什么参数的传入和传出,也不太关心。
其实是有两种方法,第一种是严格定义一个装饰函数,来对业务函数进行修饰。
另一种方法,使用@
先@一个装饰器函数,再定义一个新的函数,这样的新函数就会被@的这个装饰函数给装饰,就可以在调用业务函数时,先到装饰函数里走一遭。

@intro
def eat(……):
那具体如何变化呢?
实际使用时是,一个装饰器用在多个业务函数上。
@intro
funcA(*args)
@intro
funcB(*args)
13 经验总结 一些快速上手完整Repository的trick
先找数据输出行:看看数据输出的结构
save_df(df, is_complete_dataset, output_dir, "raw", train_metadata)
glimpse_df(df)
df = df_replace_values(df)
save_df(df, is_complete_dataset, output_dir, "clean", train_metadata)
最终输出的是一个dataframe的pkl
反向寻找定义的函数save_df,此函数内部的核心传入了输出路径与命名。数据是通过df和train_metadata
def set_defaults(**kwargs: Any) -> None
**kwargs: 这是Python函数的一种特殊参数形式,表示接受一个任意数量的关键字参数。关键字参数的形式是以 key=value 的方式传递给方法。这里的 kwargs 是参数名,实际上它是一个字典,包含所有传入的关键字参数。
例如,当调用 set_defaults(param1=value1, param2=value2) 时,kwargs 将是一个字典:{'param1': value1, 'param2': value2}。kwargs 前的两个星号 ** 表示将参数打包为字典。如果函数没有这个语法,它只能接受固定数量的参数,无法处理不确定数量的输入。
Any: 在 kwargs 后面声明了类型注解 Any,这表明 kwargs 可以是任何类型的值。Any 是Python中一个特殊的类型,表示没有具体类型的限制,可以接受任何类型。
- > None: 这是返回值的类型注解,表示该方法不返回任何值。None 是Python中表示“无返回值”或“空值”的类型,通常用于表示方法执行完毕后没有任何需要返回的内容。
is_complete_dataset = not any(map(lambda arg_name, parser=parser, args=args: is_arg_default(arg_name, parser, args), ["driver_num", "signal_duration", "epoch_events_num", "channels_ignore"]))
这部分代码涉及的语法
12 python里类class里的_init_的作用
正常情况下,直接在class里定义的变量是公共的,一旦修改,后面实例化的对象也会继承修改后的部分。初始化函数就是为了使得每个实例具有自己个性的变量。

详细讲解↓

11.如何使用git为自己的编程助力
参考教程视频:给傻子的Git教程_bilibili
Github其实就像是steam的云存档服务
存档 仓库 项目 其实三位一体 都是一个东西 Repository
Publish to github 这一步就叫做push
具体来说,先要创建存档
其余配置都很简单,现在卡在了代理配置上,需要设置一个代理配置网址
最后管用的代码
git config --global http.https://github.com.proxy socks5://127.0.0.1:10808
这里的10808是在v2ray上可以看到的
详细的参考这篇文章:设置代理解决github被墙 - 知乎
如何理解代理?待办
git log 日志,可以查看本地的各种操作
总结:通过种种操作,已经可以实现“云存档”功能,但是远远不够,现在我要寻找一个范例来跟踪学习。
参考视频:
这个教程里也很好地讲解了如何安装适配自己显卡版本的pytorch
出现了如 nvidia -smi 这样的好代码
看了一些,发现与我的方向不够契合,因此选择用下面的视频教程
10. conda环境常见指令 如何导出requirements 如何删去环境
conda list -e > requirements.txt
conda env list
conda info –envs
conda create -n 新环境名 python=3.8
deactivate
conda remove -n xxxxx(名字) --all
9. 帮我在qtdesigner里设置一个qframe的样式表,使得其有卡片一样的质感
8. property() 函数及 @property 装饰器的使用
见14
7. PyQt5已安装提示No module named ‘PyQt5.QtChart‘
Qtchart是单独的包,需要用pip单独安装。
具体命令为:
pip install pyqtchart
6.文件路径获取
用尽可能短的代码实现对我的目录dir下第一个文件绝对路径的获取
import os
dir = r'../data/mask'
files = [f for f in os.listdir(dir) if os.path.isfile(os.path.join(dir, f))]
if files:
mask_nrrd_path1 = os.path.abspath(os.path.join(dir, files[0]))
print(mask_nrrd_path1)
else:
print("No files found in the directory.")
5.5 自动化python打包程序(lose)
从一个项目入手,尝试一下,这样未来可以直接使用这样的方法来构建我的应用程序,大大省力。
先大致规划一下,主要分为几个步骤:
1. 备份我的代码,以免操作时出现失误,损失惨重
- 2. 下载并完成pyinstaller的部署
- 3. 根据教程完成打包
- 4. 出现问题先bing,再通义,再copilot
- 5. 完成打包,在其他电脑上测试
- 6. 解决测试的问题,解决思路同上
- 7. 总结
计划时间: 120min
开始!
进入官网
在这里通过pip install auto-py-to-exe 安装
通过 auto-py-to-exe 启动
成功打开这个软件,切换语言
不太理解里面几个参数怎么用,找到一个更好的介绍网站

设置导入各个文件和文件夹,点击最下方按钮
PyInstaller.isolated._parent.SubprocessDiedError: Child process died calling _is_package() with args=('skimage.io._plugins',) and kwargs={}. Its exit code was 3228369022.
Project output will not be moved to output folder
Complete.
完成后没有顺利导出
Ai告诉我是因为skimage不兼容
此外我也注意到中间TensorFlow导入时出错了
考虑使用cx_Freeze包来进行打包
根据ai的教程完成setup的配置,出现问题
RecursionError: maximum recursion depth exceeded 通常意味着在导入模块时发生了无限递归。这可能是由于 cx_Freeze 在处理某些模块或钩子时遇到了问题,导致它不断地尝试导入相同的模块。
推测是因为其中相互调用太多了,导致出现了死循环,看来还是要从单个文件练手开始,同时注意其中的引用格式
现在纠结一下是不是要继续折腾……
5.一个打包py文件的实例(lose)
为了使用`PyInstaller`将你的项目打包,你需要确保`PyInstaller`能够识别并包含你的所有必需文件和库。下面是一个基于你提供的文件结构的打包命令示例:
假设你的目录结构如下:
```
D:\Code\Python\TZB2024\ui
├── __pycache__
├── data
├── dll
├── main.py
└── VER1.ui
```
你想要将打包后的文件放到 `D:\Code\Python\TZB2024` 目录下。
### 第一步:编写.spec文件
首先,你可能需要创建一个`.spec`文件,这将告诉`PyInstaller`如何构建你的应用。打开文本编辑器,创建一个新的文件,并将其命名为 `main.spec`(或者任何你喜欢的名字)。将以下内容粘贴到该文件中:
这个`.spec`文件包含了以下信息:
- `Analysis` 部分指定了主要的Python脚本 (`main.py`) 和其所在目录。
- `binaries` 参数用来指定`dll`文件夹的位置和它应该被包含的方式。
- `datas` 参数用来指定`data`文件夹和UI文件的位置以及它们应该被包含的方式。
- `EXE` 部分定义了最终的可执行文件的属性,包括它的名字 (`name='TZB2024'`) 和是否使用控制台 (`console=False`)。
### 第二步:运行PyInstaller
在你的命令行工具中,导航至包含`main.spec`文件的目录,然后运行以下命令:
```bash
pyinstaller D:\Code\Python\TZB2024\ui\main.spec
```
这将会使用你刚刚创建的`.spec`文件来构建你的应用。默认情况下,`PyInstaller`会在`D:\Code\Python\TZB2024\ui\dist`目录下生成可执行文件。要改变输出目录,你可以在.spec文件中修改`distpath`参数,或者使用命令行参数`--distpath`。
### 第三步:移动输出文件
打包完成后,你可以手动将`dist`目录下的文件移动到`D:\Code\Python\TZB2024`目录下,或者通过脚本自动化这个过程。
Auto,但还没试过
4 python中文件路径的写法
注意区分 / 与 \
其中 / 是正斜杠,在Linux与macOS里用,而反斜杠 \ 则更多用于windows系统
3 网站开发记录 8.3
使用Notion的尝试:
获得一个模板,share从而得到网址:https://knotty-equinox-49a.notion.site/fa88ffa6f02e4dd09bd9cb7bbef97960?v=17fa249218b049148b2fc624457dab42&pvs=4
页面ID fa88ffa6f02e4dd09bd9cb7bbef97960
通过eu.org获取自己的免费域名,使用了一个生成的英国用户信息
在Vercel进行配置
完成配置后,总的来说,使用三个网站进行综合管理:
Notion进行内容的管理,Git上的代码对底层逻辑进行修改(类似JavaScript的作用),Vercel对域名和网站的流量、历史版本等进行管理
(还有腾讯云用于托管域名,背后的玄机暂未理解)
最后的方案是用cloudfare加nameiso两个解决的,第一年一共花了7块钱
有时间再写吧
2 ui开发中的记录 8.3
我的文件读取实现是通过在qtdesigner里放置一个叫做fileup_1的pushbutton,然后点击后可以打开一个窗口,上传文件至与代码同一目录下的data\1文件夹内,并在一个叫做list的QlistWidget中显示文件名
同理我的fileup_2的pushbutton,然后点击后可以打开一个窗口,上传文件至与代码同一目录下的data\2文件夹内,并在一个叫做list_1的QlistWidget中显示文件名
对几个widget进行排版
学到一个核心技术,不必先建一个frame,可以直接对两个部件进行排版,大大简化过程,也避免了很多bug
设置stackwidget的布局
卡在了布局的一个神秘bug上,我的page1可以顺利设置布局,但是page2等其他page却不行,好奇怪!
###一个实用的经验,在中心界面右键widget忽然就可以设置layout了
开一个坑:openGL似乎可以实时显示点云!有时间看看怎么用
在我的main代码里调用我同一父目录下的dll\pic_generate.py文件,在我的界面中我只要点击我的fileup_1这个pushbutton就可以调用这个文件
现在我要联系我的pic1这个QGraphicsView和horizontalSlider_2这个Qslider,使得我拖动slider时,pic1里显示的图片能够依次切换,我的pic1里的图片全都来自于dir_pic1这个目录
我的文件格式如下,所有文件都在D:\Code\Python\TZB2024\ui这个目录下,里面有__pycache__,data,dll,这三个文件夹和main.py、VER1.ui这两个文件,其中data里面用于放置各种程序运行中产生的数据,dll里有各种需要调用的库
请帮我写一个完整的打包代码,把打包后的文件放在D:\Code\Python\TZB2024目录下
下面是我的一个函数库,我要在main函数里调用里面的read_dcm和save_as_folder这2个函数来对我上传的dcm文件进行处理,并将图像保存到我的show/rawdata里面
把分割代码的数据转成了cpu
那个分割模型,我先是转到cpu计算避免用户显卡驱动和cuda版本不对应,然后简单优化,但是现在单独能跑,在程序里调用跑不动,我在de这个bug
我在使用qtdesiner和下面的main代码来制作我的ui,要在ui里点击view3d这个Qpushbutton调用我的dll. 3d_view这个代码
作为背景,一个非常漂亮的Qwidget的背景的样式表,要求主色调为浅蓝色
我用下面的代码调用我的ui文件,却出现了AttributeError: type object 'Qt' has no attribute 'QFrame::Shape::NoFrame'的报错
使用qtdesiner和下面的main代码来制作我的ui,添加功能:
点击divide_pic1后,不仅调用分割函数,还可以将函数生成的nrrd文件利用利用我的read_nrrd来读取,再使用save_as_folder来对其进行图像的生成和保存(保存至.\data\show\slicepic里)
右边的代码,直接运行没问题,但是在其他文件里调用其中的函数,会显示FileNotFoundError: [Errno 2] No such file or directory: 'MGUNet1.pt'
——应该是工作路径变化了,无法识别
Python里,我在代码A中通过import dll.B来调用B里面的函数,但是B里面又通过import utils.C来调用C代码里的函数,运行A时工作目录是A代码的目录,可以读取到B,但是无法在B中继续读取C
###解决:哪个文件运行就是在那个文件的目录下找文件,运行 A的时候,把C中的import以A为参考系来导入
此外,init可能也很有用?
模仿里面的change_picture1写一个change_picture3,把horizontalSlider_5和slicepic1_b这个graphicsview联系到一起,需要在哪些地方添加哪些代码
在__init__方法中添加对horizontalSlider_4和slicepic1_a的引用。
添加一个新的方法change_picture4来处理滑块改变时的行为。
将horizontalSlider_4的valueChanged信号连接到change_picture4方法。
做到滑动一个slicer就能同步控制两个graphicsview改变图像
如何让正在运行的代码,在我的UI中显示进度条
我在使用qtdesiner和下面的main代码来制作我的ui,我要添加功能:实现点击part3button就能调用我的process_dicom_files(dicom_directory, output_directory)函数
我的output_directory = "./data/show/yingbianpic"中的3张图片,能分别在yb1,yb2,yb3这3个graphicsview中呈现
似乎遇到了多线程运行的问题,或是某个函数反复运行
###应该在每个函数后边加一个中断信号的代码
self.XXbutton.clicked.disconnect()
将这里边print的内容输入additem到我的list_widget_2里
测试一下
将这个代码整体的调用进行封装,传入必要的参数
我的代码classit(config)计算需要一段时间,我该如何用进度条来展示我现在的进度,必须要修改我的classit的写法吗?
self.progressbarC.setValue(88)解决问题
主窗口的大小设置
应该对其中的centralwidget进行操作,才能完成窗口大小的调整,理解一下便是主窗口是在适应唯一一个widget的大小
无边框设置
关于一个layout里的布局使用方法
###点击layout,里面会有layoutstrech这个值,如果是两个控件在里面就是a,b,有三个就是a,b,c,通过这个来调整比例,值得注意的是要先将空间设置为prefer的策略
如何在我的qtdesigner里给我的ui加一个图标
添加资源
现在我是动态读取的ui文件,我在qtdesigner里设置了对应的icon,—pyqt5 动态读取ui文件的时候识别不了我的qrc资源
###只需要先转qrc为py文件,再import进去即可,设置相关的在ui文件里包含了,from img import *
对于我的下面的函数,这个函数在点击divide_pic1这个button后会开始被调用进行分割计算,现在我要在pyqt5中利用QprogressBar来实现进度的实时呈现,修改函数和主代码
写一个韩式def save_as_folder(image, base_dir, cmap='gray', choose_axis=['Axial', 'Coronal', 'Sagittal'], save_every_nth=100):实现读取base_dir
点击我的PART1这个button后,设置我的button1,button2的样式表中的 background-color变成qlineargradient(x1: 0, y1: 0, x2: 1, y2: 1, stop: 0 #5C67F0, stop: 1 #9FA8DA); border变成 1px solid #4A54E1;
请问我connect的on_PART1_clicked应该怎么改
神秘bug,修改了connect还是可以运行对应的函数
写一个函数,在我的ui中点击detail这个button后,可以打开我的“field_dir=r'../data/result/field' 读取里面的第一个csv,def on_detail_clicked(self):
现在点击detail_2打开.\data\show\partC\strain里的第一个文件
一些血的教训
1.队友一定要教会他们如何做接口
2.对于各个功能的实现需要知道预期的时间,但是没有过经验又确实不知道要做多久,本质还是矛盾的
3.对于对方给的每一个函数,不要太自信自己去修改,应该让对面改到合适才行
1.库安装,使用清华源 8.3
前言
在这里开个坑。
这是一件想做了很久的事,也有过一些已经被忘记的深思熟虑:起因是在写一个有一定规模的项目时遇到的困境,那就是GPT很难理解我们的整个项目,难以构建起多个代码与文件之间的串联。在多次的使用中能很明显地发现它的适用场景还是偏向一些独立的小功能上,可以简单提升Code效率。简而言之,是一个很好的小工具,但不适合长期使用。
再者便是看到身边的同学,一种源自peer pressure的动力。在GPT的帮助下,越来越多的人开始使用机器学习、深度学习等来丰富自己的课题,这也确实带来了一些焦虑——自己的技术壁垒是否构筑起来了?
因此这里就显得很有必要,我需要这样一个地方来安置我的各种所学,像背英语单词一样,在使用中渐渐记住各种用法,各种常见的bug,从而在下一次能快速反应过来,如是,方将技能内化为自己的一部分,而不是浮于表面。
用txt可以尽可能降低这个记录对于内存的负荷,降低的记录门槛
一个好的格式应当可以事半功倍,方便检索
Relate Posts
